

I’m a Spartan racer and Obstacle Course Racing (OCR) enthusiast! And…. I work at MapR. Since data matters in sports performance, I pondered if we could combine the power of both Spartan and MapR to create an epic data experience. The first goal was: “As a Spartan racer, I want to be able to see my past results and the results of any other racer with just one search”. This is part one of a mini-series that journeys through the data import into MapR and subsequently analyzes the global Spartan race results.
The obstacles to overcome and achieve this goal are:
- Fetch the Spartan race results
- Load the race results data into MapR (DB and Streams)
- Query the race results quickly
Obstacle 1: Fetch the data (you can skip this obstacle)
The code that fetches the data is written in python. After fetching the data, it writes the course results to json files on the local filesystem. See this github repo to read more about that data fetch logic that pulls data from Spartan and Athlinks.
# fetchData
events : from spartan api :
]{"event_name":"Spartan World Championship","subevents": [{"event_name": "Lake Tahoe Beast","race_id":"677643"}]} -- subevent has the race_idraces : from athlinks api
course_results : (Athlinks API)(contains results for each spartan athlete)
One point of interest is in the json library that is used in the python code. Rather than use the standard json library that ships with python, this project leverages ‘ujson’ for purely performance reasons. My client logic that reads / writes from the filesystem is slightly inefficient in that it writes every unique race and course_results to a unique file. This results in lots of json files and lots of IO. From our testing, ujson was much more performant for many reads and reads (loads and dumps); hence, our choice in ujson.
Obstacle 2: Load the race results data into MapR (DB and Streams)
To load the data, an understanding of the data flow is required.
- Copy json racing results files from local filesystem to HDFS
- Create MapR DB tables, secondary indexes, and changelog streams
- Load the race results data from HDFS into MapR DB
The script to load the dataset into MapR FS can be found here. To leverage the script, do the following via the terminal.
ssh_to_your_node
su mapr
maprlogin password #if secure cluster
cd /tmp/
wget https://raw.githubusercontent.com/sogwiz/spartan/master/analytics/mapr/data_setup.sh .
chmod 755 data_setup.sh
./data_setup.shYou’ll note that the script creates a secondary index with covered fields to ensure fast query performance.
The secondary index achieves better performance via a special table that:
- stores a subset of document fields from a json table -> smaller data set to sift through
- orders its data on a set of fields (indexed fields) -> sorted data need not be scanned in its entirety
#create a secondary indexes
maprcli table index add -path $TABLE_COURSE_RESULTS -index racer_display_name -indexedfields \
DisplayName -includedfields CourseID,CourseName,CoursePattern,RaceID,event_id,Age,BibNum,RacerID,Ticks,TicksString
maprcli table index add -path $TABLE_COURSE_RESULTS -index racer_id -indexedfields \
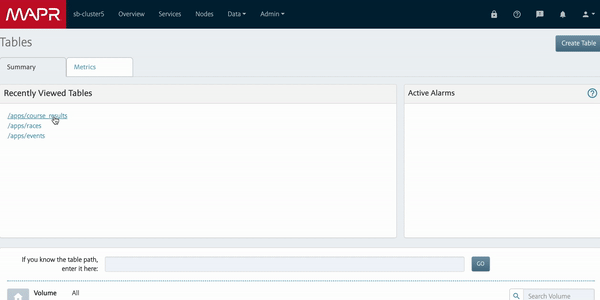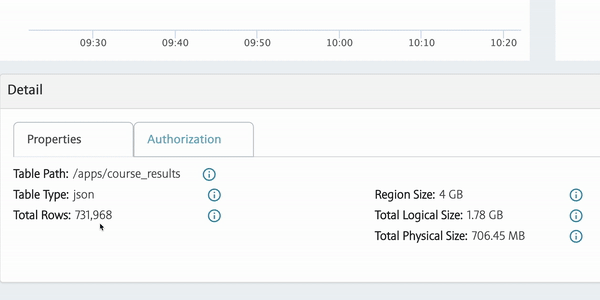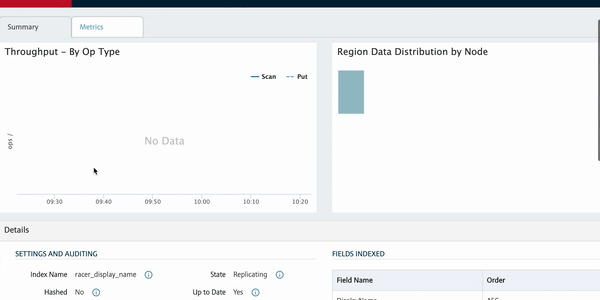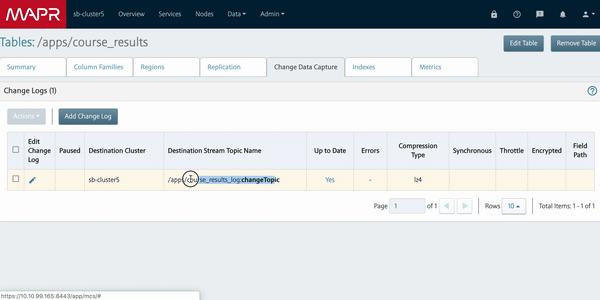
RacerID -includedfields CourseID,CourseName,CoursePattern,RaceID,event_id,Age,BibNum,DisplayName,Ticks,TicksStringOnce the data load is complete into MapR, we can view the tables in the MapR Control System (MCS). We can also view the secondary indexes and change logs that we’ve created.
Obstacle 3: Query the race results quickly
Now that we have the data in MapR, we can start the real fun. I’ve included example queries using both Go and Python, leveraging the OJAI language bindings. These client binding libraries make it seamless for an app developer to create a user experience that responds quickly to user queries. This is made possible thanks to the power of the secondary index MapR DB feature.
Python
connection = ConnectionFactory.get_connection(self.connection_string)
document_store = connection.get_store(store_path='/apps/course_results')
1 query_dict = {"$select":["event_id","RaceID","CourseName","CoursePattern","DisplayName",\
"TicksString"],\"$where":{"$like":{"DisplayName":user} }}
2
3 start = time.time()
4 query_result = document_store.find(query_dict,options=self.options)Go
query := map[string]interface{}{"$select": []interface{} \
{"CourseName", "RaceID"},
"$where": \
map[string]interface{}{
"$like": map[string]interface{}{"DisplayName": "sargon%benjamin"}}}
findResult, err := store.FindQueryMap(query, options)
iterations := 0
for _, doc := range findResult.DocumentList() {
fmt.Println(doc)
iterations+=1
}In the next post, we’ll slice and dice the data with Drill and Spark
Recent Comments